solarized light
Foundations of Linear Regression
Let's begin our journey into linear regression by first understanding what it is, and why it is so important in data science.
Linear regression is a statistical method used to model the relationship between two or more variables. It is a very simple, yet powerful, method that is used in many different fields. In data science, it is used to understand the relationship between variables in a dataset, and to predict the value of a variable given the value of another variable.
Let's take a look at a simple example using the iris dataset. We will use the sepal length and petal length variables to illustrate the concept of linear regression. In this example, we will use sepal length as the independent variable, also known as the explanatory variable or feature; this is the variable that we assume influences or predicts the dependent variable, which is the variable of interest. We will use petal length as the dependent variable, also known as the response variable, outcome variable, or target. Due to how much linear regression is used in a variety of fields there are many different terms that refer to the same thing, so one challenge starting out is just becoming familiar with the terminology that is more common in your field of interest.
Let's take a look at the plot of these two variables with the best fit line added in (the black line in the plot below). The best fit line is the line that minimizes the distance between all the points in the plot. We will discuss how to calculate this line shortly.
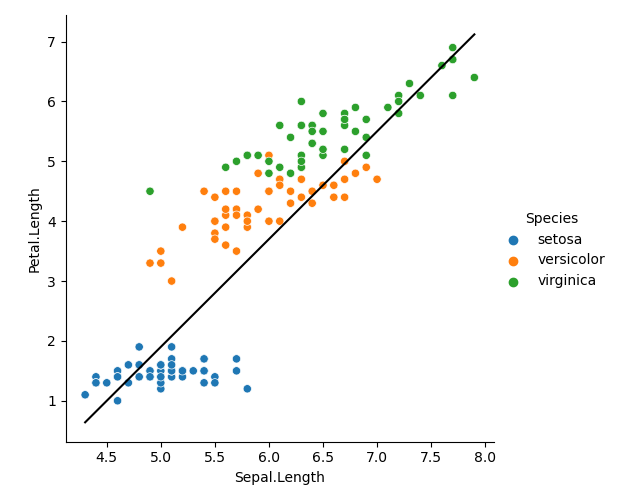
We can see that there is a clear relationship between the two variables, and that the best fit line does a good job of capturing this relationship. We can also see that the best fit line is not perfect, and that there is some variation in the data. This variation is due to the fact that there may be either other variables that influence petal length that we are not accounting for in this model, or that additional complexity between the two variables exists that we are not capturing with a straight line. Next, let's go over the the equation for this line, before concluding with going over the code that produced this plot.
Equation of a line
The linear regression model is the following equation:
Let's go over what each of these variables mean in the next few sections.
The dependent variable: y
The dependent variable is the variable that we want to learn more about.
In our example, this is the petal length variable.
In the equation, it is represented by the variable
The independent variable: x
The independent variable is the variable that we hypothesize influences
the dependent variable. In our case, sepal length and represented
in the equation as
The slope: m
The slope, represented by
For example, let's look at the plot below. The slope is positive,
with m = 0.5. We put a black line from the x-axis at
sepal length = 6 to sepal length = 7. Since
the difference between 7 and 6 is 1, we call this
a unit change. We can see that the difference between petal length
at these two endpoints is is roughly 5.5 - 3.5 = 2,
which is close to the the slope we calculated earlier at 1.8.
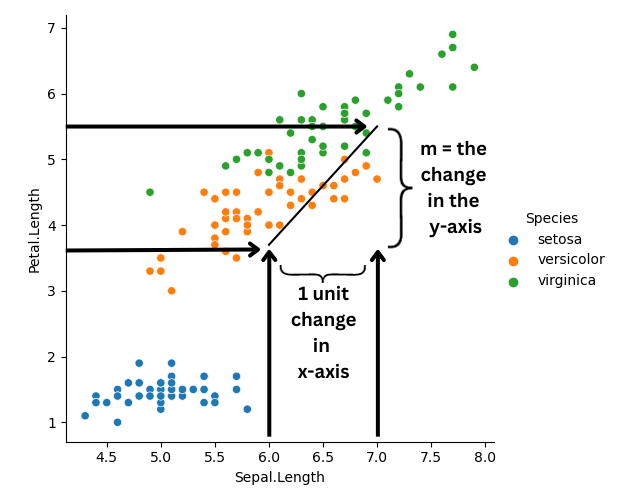
The intercept: b
The intercept, represented by
The error: \varepsilon
The error, represented by
The code that produced the plot
To conclude this lesson let's go over the code line-by-line that produced the plot. Note that the libraries we imported are hidden in the code below, if you want to see what they are, check out the Code environment drop-down menu at the top of the page.
- Line 2: This plots the iris dataset with sepal length on the x-axis and petal length on the y-axis.
- Lines 5 & 6: We will see in the next lesson how to calculate these. For now, just know that these are the values of the slope and intercept.
- Line 9: To formulate this in the same way as the
equation we create the
x variable. - Line 12: We use the slope, intercept and
x to calculate the predicted\hat{y} (y_hatvalues) for the best fit line. - Lines 15: We add the best fit line to the plot. We
use the
sns.lineplotalong with theaxargument to add the line to the existing plot specifying the plot with theplot.axvalue.
solarized light
